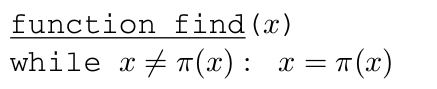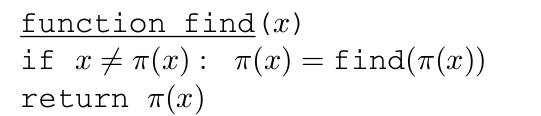算法设计与分析[0007] Minimum Spanning Tree(最小生成树)
本文将介绍带权图的最小生成树(Minimum Spanning Tree)算法:给定一个无向图 G,并且它的每条边均有权值,则 MST 是一个包括 G 的所有顶点及边的子集的图,这个子集保证图是连通的,并且子集中所有边的权值之和为所有子集中最小的。
Minimum spanning trees
让所有节点都被连接的最佳边集合:不可能包含环。
移除环中的任何一条边都会降低代价而不破坏连通性 (所有节点都被连接)。
树 是一种连通且无环的无向图。
性质①:移除环中的任意一条边不会破坏图的连通性。
性质②:具有 n 个节点的树的边数为 n-1。
n 个节点,n 个独立的连接部件。
边 ${u, v}$ 的两个顶点分别处于两个独立的连接部件,否则,必然已存在连接两者的一条路径, ${u, v}$ 将导致环的出现。
每添加一条边,总的连接部件数减少了 1,从 n 一步步减少到 1,需要添加 n-1 条边。
性质③:任何一个连通无向图 $G = (V, E)$,若满足 $|E| = |V| - 1$,则其为树。
如果 G 中包含一个环,则移除该环上任意一边,直到得到一个无环图。
G’ 是连通的(性质①),且无环,故为树,故 $|E’| = |V| - 1$(性质②),实际上并没有移除过任意一条边,其本身就是树,即 $G’ = G$。
性质④:一个无向图是树,当且仅当在其任意两个节点间仅存在唯一路径。
任意两个节点间都存在一条路径 ===> 连通性
路径唯一 ===> 无环,环必然使得任意两个节点间存在两条路径
最小生成树 :具有最小代价(总权重)的树
图的生成树是它的一棵含有其所有顶点的无环连通子图,一幅加权图的最小生成树(MST)是它的一棵权值(树中的所有边的权值之和)最小的生成树。
树$T = (V, E’)$,其中 $E \subseteq E’$,使得权重 $weight(T) = \sum_{e \in E’} w_e$ 最小。
Prim 算法
References:
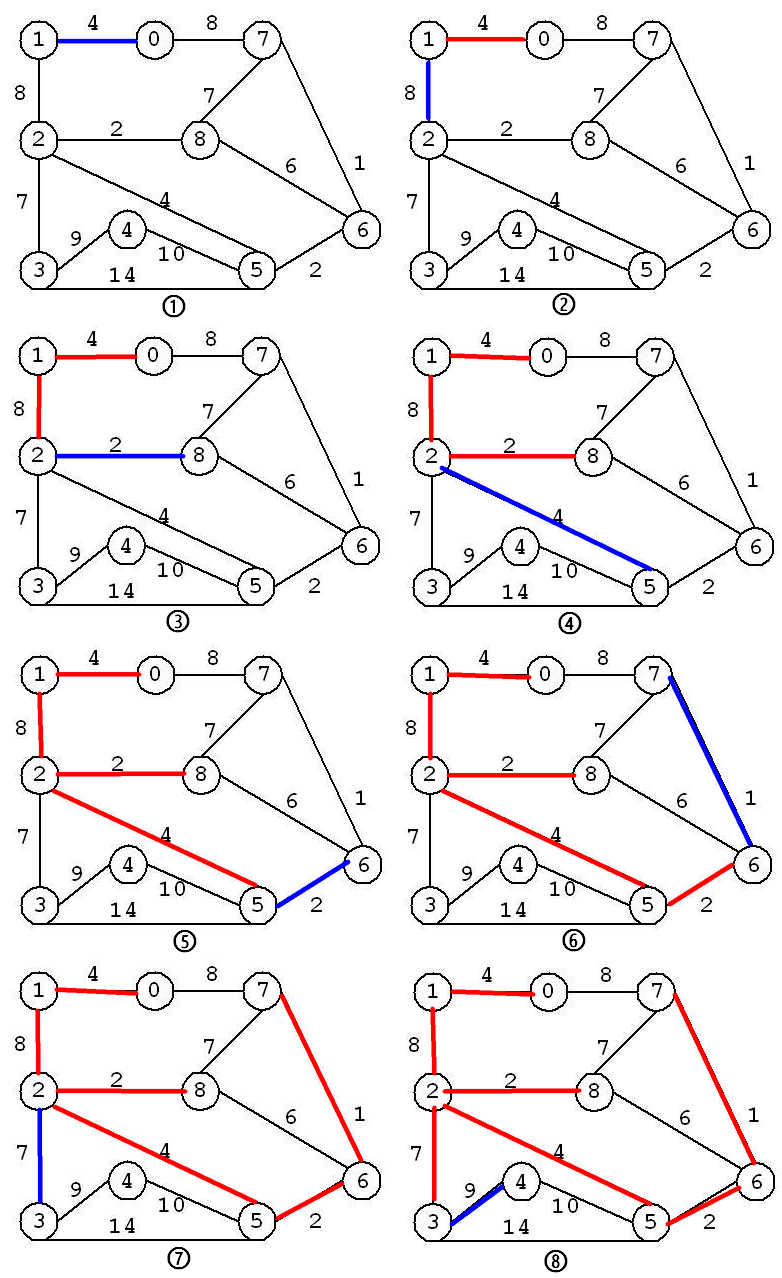
Prim 算法可以说是所有 MST 算法中最简单的,比较适用于稠密图。以图中任意一个顶点 s 开始,MST 初始化为 :{ V(s), E(none) }(顶点,边),称之为“当前 MST”,选择与当前 MST 中所有顶点相关连的边中权值最小的边,并添加到当前 MST 中。这一过程一直迭代到图中所有顶点都添加到 MST 中为止。
在迭代时,假设当前 MST 中顶点形成集合 $V(v_0, v_1, …)$,则对 $V(v_0, v_1, …)$ 中的每一个 $v_i$,遍历与其相邻的所有边,并找到权值最小的边。
Prim 最小生成树算法与 Dijkstra 最短路径算法 十分相似,只不过 Prim 算法里节点的值是该节点到当前最小生成树中所有节点的边中的最短长度,而 Dijkstra 算法中节点的值是该节点到源节点的当前最短路径长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 #include <iostream> #include <stdio.h> /* stdin */ #include <limits.h> /* INT_MAX */ using namespace std ; #define MAX_VERTEX_NUM 26 struct adjVertexNode { int adjVertexIdx; int weight; adjVertexNode* next; }; struct VertexNode { char data; adjVertexNode* list ; int cost; VertexNode* prev; }; struct Graph { VertexNode VertexNodes[MAX_VERTEX_NUM]; int vertexNum; int edgeNum; }; void CreateGraph (Graph& g) int i, j, edgeStart, edgeEnd, weight; adjVertexNode* adjNode; cin >> g.vertexNum >> g.edgeNum; for (i=0 ; i<g.vertexNum; i++) { cin >> g.VertexNodes[i].data; g.VertexNodes[i].list = NULL ; g.VertexNodes[i].prev = NULL ; } for (j=0 ; j<g.edgeNum; j++) { cin >> edgeStart >> edgeEnd >> weight; adjNode = new adjVertexNode; adjNode->adjVertexIdx = edgeEnd; adjNode->weight = weight; adjNode->next = g.VertexNodes[edgeStart].list ; g.VertexNodes[edgeStart].list = adjNode; } } void PrintAdjList (const Graph& g) cout << "The adjacent list for graph is:" << endl ; for (int i=0 ; i < g.vertexNum; i++) { cout << " " << g.VertexNodes[i].data << "->" ; adjVertexNode* head = g.VertexNodes[i].list ; if (head == NULL ) cout << "NULL" ; while (head != NULL ) { cout << g.VertexNodes[head->adjVertexIdx].data << "(" << head->weight << ") " ; head = head->next; } cout << endl ; } } void DeleteGraph (Graph& g) for (int i=0 ; i<g.vertexNum; i++) { adjVertexNode* tmp = NULL ; while (g.VertexNodes[i].list != NULL ) { tmp = g.VertexNodes[i].list ; g.VertexNodes[i].list = g.VertexNodes[i].list ->next; delete tmp; tmp = NULL ; } } } void Prim (Graph& g, int start=0 ) bool visited[g.vertexNum]; for (int i=0 ; i<g.vertexNum; i++) { g.VertexNodes[i].cost = INT_MAX; g.VertexNodes[i].prev = NULL ; visited[i] = false ; } cout << "MST constructing:" << endl ; g.VertexNodes[start].cost = 0 ; for (int vertexNuminMST = 0 ; vertexNuminMST < g.vertexNum; vertexNuminMST++) { int minCost = INT_MAX; int pickIdx = -1 ; for (int i=0 ; i<g.vertexNum; i++) { if (!visited[i] && g.VertexNodes[i].cost<minCost) { minCost = g.VertexNodes[i].cost; pickIdx = i; } } if (pickIdx == -1 ) { break ; } visited[pickIdx] = true ; if (g.VertexNodes[pickIdx].prev != NULL ) { cout << "\t+ " << g.VertexNodes[pickIdx].data << "-->" << g.VertexNodes[pickIdx].prev->data << "(" << g.VertexNodes[pickIdx].cost << ")" << endl ; } VertexNode* v = &g.VertexNodes[pickIdx]; adjVertexNode* head = v->list ; while (head != NULL ) { if (!visited[head->adjVertexIdx] && g.VertexNodes[head->adjVertexIdx].cost > head->weight) { g.VertexNodes[head->adjVertexIdx].cost = head->weight; g.VertexNodes[head->adjVertexIdx].prev = v; } head = head->next; } } } void PrintMST (Graph& g) int cost = 0 ; for (int i=g.vertexNum-1 ; i>=0 ; i--) { if (g.VertexNodes[i].prev != NULL ) { cout << "\t+ " << g.VertexNodes[i].data << "<--" << g.VertexNodes[i].prev->data << "(" << g.VertexNodes[i].cost << ")" << endl ; cost += g.VertexNodes[i].cost; } } cout << " cost: " << cost << endl ; } int main (int argc, const char ** argv) freopen("Prim.txt" , "r" , stdin ); Graph g; CreateGraph(g); PrintAdjList(g); Prim(g); cout << endl ; cout << "Minimum Spanning Tree: " << endl ; PrintMST(g); DeleteGraph(g); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ g++ Prim.cpp -o Prim $ ./Prim The adjacent list for graph is: 0->7(8) 1(4) 1->2(8) 0(4) 2->8(2) 5(4) 3(7) 1(8) 3->5(14) 4(9) 2(7) 4->5(10) 3(9) 5->6(2) 4(10) 3(14) 2(4) 6->8(6) 7(1) 5(2) 7->8(7) 6(1) 0(8) 8->7(7) 6(6) 2(2) MST constructing: + 1-->0(4) + 2-->1(8) + 8-->2(2) + 5-->2(4) + 6-->5(2) + 7-->6(1) + 3-->2(7) + 4-->3(9) Minimum Spanning Tree: + 8<--2(2) + 7<--6(1) + 6<--5(2) + 5<--2(4) + 4<--3(9) + 3<--2(7) + 2<--1(8) + 1<--0(4) cost: 37
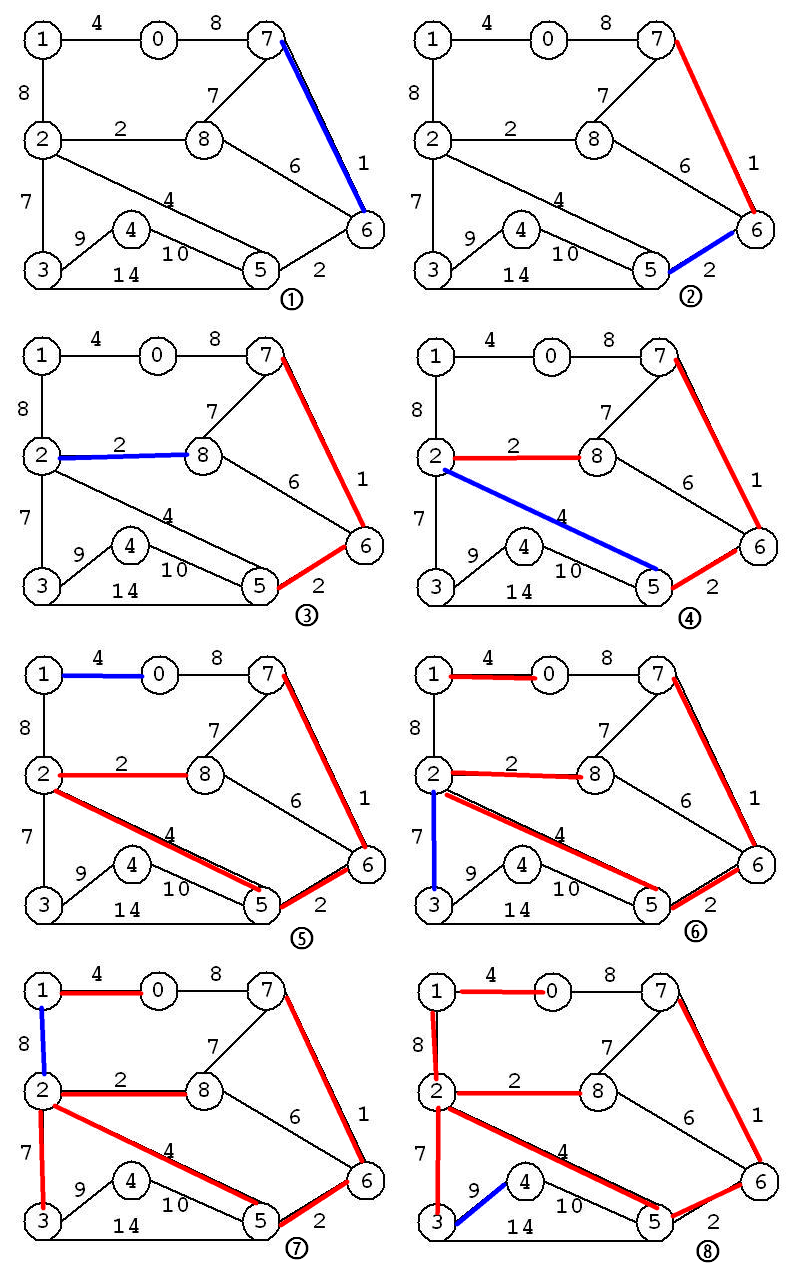
整棵最小生成树的构建过程如下:
上述无向图对应的输入文件 Prim.txt 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 9 26 0 1 2 3 4 5 6 7 8 0 1 4 0 7 8 1 0 4 1 2 8 2 1 8 2 3 7 2 5 4 2 8 2 3 2 7 3 4 9 3 5 14 4 3 9 4 5 10 5 2 4 5 3 14 5 4 10 5 6 2 6 5 2 6 7 1 6 8 6 7 0 8 7 6 1 7 8 7 8 2 2 8 6 6 8 7 7
从上述的实现过程可以发现,在遍历与顶点相邻的所有边寻找与当前 MST 最近的顶点时,需要进行循环判断,选择距离最近的边之后其余边的信息将被舍弃;在下次循环判断时这些舍弃的边又被再次参与“竞选”最近的边,这无疑带来了重复判断。可以引入一个 最小堆 ,堆中存放遍历过的边。在遍历与顶点相邻的所有边时,首先将连边添加到堆中,然后直接将堆顶的边取出并添加到 MST 中。这样就可以避免重复判断。
基于 std::priority_queue 优先级队列的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 #include <iostream> #include <stdio.h> /* stdin */ #include <limits.h> /* INT_MAX */ #include <queue> /* priority_queue */ using namespace std ; #define MAX_VERTEX_NUM 26 struct adjVertexNode { int adjVertexIdx; int weight; adjVertexNode* next; }; struct VertexNode { char data; int vertexIdx; adjVertexNode* list ; int cost; VertexNode* prev; bool operator < (const VertexNode& right) const { return cost > right.cost; }; }; struct Graph { VertexNode VertexNodes[MAX_VERTEX_NUM]; int vertexNum; int edgeNum; }; void CreateGraph (Graph& g) int i, j, edgeStart, edgeEnd, weight; adjVertexNode* adjNode; cin >> g.vertexNum >> g.edgeNum; for (i=0 ; i<g.vertexNum; i++) { cin >> g.VertexNodes[i].data; g.VertexNodes[i].vertexIdx = i; g.VertexNodes[i].list = NULL ; g.VertexNodes[i].prev = NULL ; } for (j=0 ; j<g.edgeNum; j++) { cin >> edgeStart >> edgeEnd >> weight; adjNode = new adjVertexNode; adjNode->adjVertexIdx = edgeEnd; adjNode->weight = weight; adjNode->next = g.VertexNodes[edgeStart].list ; g.VertexNodes[edgeStart].list = adjNode; } } void PrintAdjList (const Graph& g) cout << "The adjacent list for graph is:" << endl ; for (int i=0 ; i < g.vertexNum; i++) { cout << " " << g.VertexNodes[i].data << "->" ; adjVertexNode* head = g.VertexNodes[i].list ; if (head == NULL ) cout << "NULL" ; while (head != NULL ) { cout << g.VertexNodes[head->adjVertexIdx].data << "(" << head->weight << ") " ; head = head->next; } cout << endl ; } } void DeleteGraph (Graph& g) for (int i=0 ; i<g.vertexNum; i++) { adjVertexNode* tmp = NULL ; while (g.VertexNodes[i].list != NULL ) { tmp = g.VertexNodes[i].list ; g.VertexNodes[i].list = g.VertexNodes[i].list ->next; delete tmp; tmp = NULL ; } } } void Prim (Graph& g, int start=0 ) priority_queue<VertexNode> vertexQueue; bool visited[g.vertexNum]; for (int i=0 ; i<g.vertexNum; i++) { g.VertexNodes[i].cost = INT_MAX; g.VertexNodes[i].prev = NULL ; visited[g.VertexNodes[i].vertexIdx] = false ; } g.VertexNodes[start].cost = 0 ; for (int i=0 ; i<g.vertexNum; i++) { vertexQueue.push(g.VertexNodes[i]); } cout << "\nMST constructing:" << endl ; while (!vertexQueue.empty()) { #ifdef PRINT priority_queue<VertexNode> printQueue = vertexQueue; cout << endl ; while (!printQueue.empty()) { VertexNode tmp = printQueue.top(); printQueue.pop(); if (tmp.cost != INT_MAX) { cout << tmp.data << "(" << tmp.cost << ")" << " " ; } else { cout << "." ; } } #endif VertexNode v = vertexQueue.top(); #ifdef PRINT cout << "\n\tpop: " << v.data << "(" ; if (v.cost != INT_MAX) { cout << v.cost; } else { cout << "INF" ; } cout << ")" << " " ; #endif vertexQueue.pop(); int vertexIdx = v.vertexIdx; if (visited[vertexIdx]) { #ifdef PRINT cout << endl ; #endif continue ; } visited[vertexIdx] = true ; if (g.VertexNodes[vertexIdx].prev != NULL ) { cout << "\t+ " << g.VertexNodes[vertexIdx].data << "-->" << g.VertexNodes[vertexIdx].prev->data << "(" << g.VertexNodes[vertexIdx].cost << ")" << endl ; } #ifdef PRINT cout << "push: " ; #endif adjVertexNode* head = v.list ; while (head != NULL ) { if (!visited[head->adjVertexIdx] && g.VertexNodes[head->adjVertexIdx].cost > head->weight) { g.VertexNodes[head->adjVertexIdx].cost = head->weight; g.VertexNodes[head->adjVertexIdx].prev = &g.VertexNodes[v.vertexIdx]; vertexQueue.push(g.VertexNodes[head->adjVertexIdx]); #ifdef PRINT cout << g.VertexNodes[head->adjVertexIdx].data << "(" << g.VertexNodes[head->adjVertexIdx].cost << ")" << " " ; #endif } head = head->next; } #ifdef PRINT cout << endl ; #endif } } void PrintMST (Graph& g) int cost = 0 ; for (int i=g.vertexNum-1 ; i>=0 ; i--) { if (g.VertexNodes[i].prev != NULL ) { cout << "\t+ " << g.VertexNodes[i].data << "<--" << g.VertexNodes[i].prev->data << "(" << g.VertexNodes[i].cost << ")" << endl ; cost += g.VertexNodes[i].cost; } } cout << " cost: " << cost << endl ; } int main (int argc, const char ** argv) freopen("Prim.txt" , "r" , stdin ); Graph g; CreateGraph(g); PrintAdjList(g); Prim(g); cout << endl ; cout << "Minimum Spanning Tree: " << endl ; PrintMST(g); DeleteGraph(g); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ g++ Prim_queue.cpp -o Prim_queue $ ./Prim_queue The adjacent list for graph is: 0->7(8) 1(4) 1->2(8) 0(4) 2->8(2) 5(4) 3(7) 1(8) 3->5(14) 4(9) 2(7) 4->5(10) 3(9) 5->6(2) 4(10) 3(14) 2(4) 6->8(6) 7(1) 5(2) 7->8(7) 6(1) 0(8) 8->7(7) 6(6) 2(2) MST constructing: + 1-->0(4) + 7-->0(8) + 6-->7(1) + 5-->6(2) + 2-->5(4) + 8-->2(2) + 3-->2(7) + 4-->3(9) Minimum Spanning Tree: + 8<--2(2) + 7<--0(8) + 6<--7(1) + 5<--6(2) + 4<--3(9) + 3<--2(7) + 2<--5(4) + 1<--0(4) cost: 37
整棵最小生成树的构建过程如下:
Kruskal 算法
References:
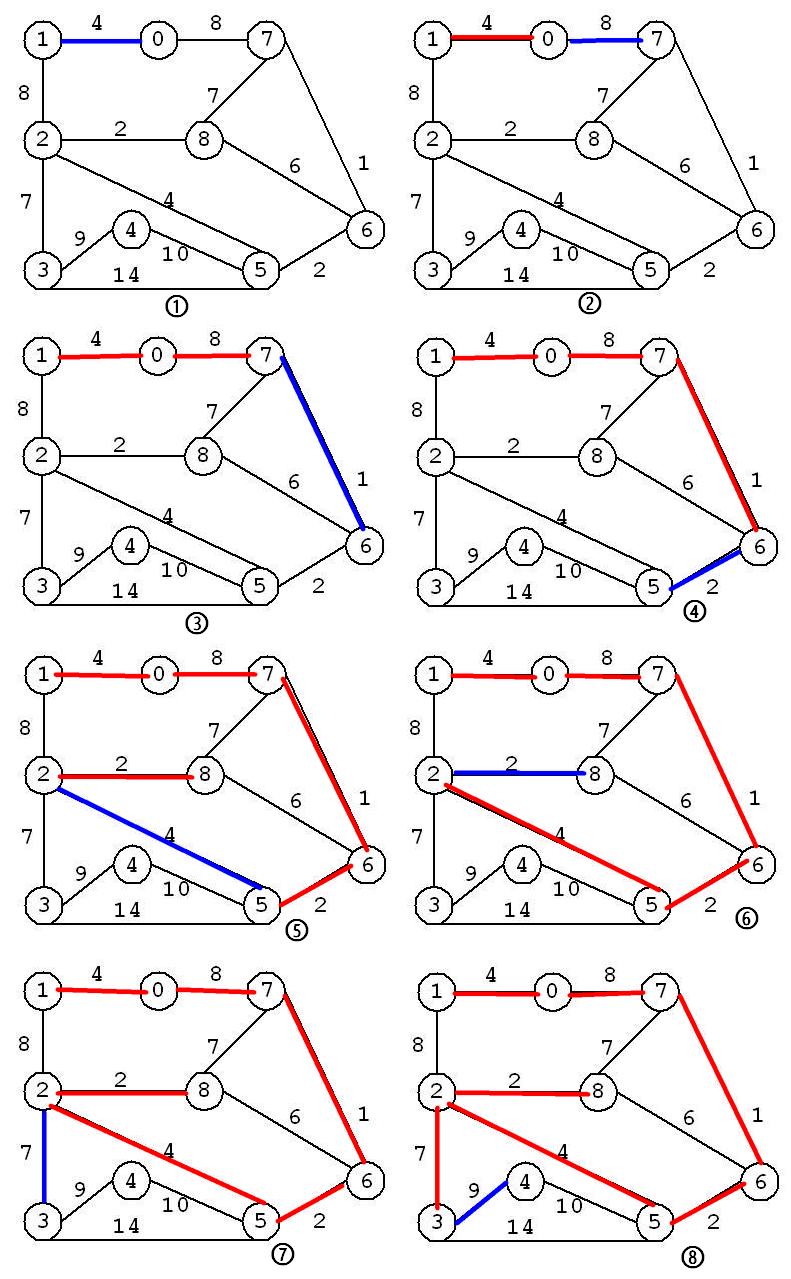
Prim 算法的思路是通过一次找出一条边添加到 MST 中,其中每一步都是要找到一条新的边并且关联到不断增长的当前 MST。Kruskal 算法也是一次找到一条边来不断构建 MST,但是与 Prim 算法不同的是,它要找到连接两棵树的一条边,这两棵树处于一个 MST 子树的分离的森林中,其中 MST 子树将不断增长。
算法由一个包括 N 棵(单个顶点组成的)树的森林开始。然后持续完成合并两棵树的操作(使用最短的边连接它们),直至只剩下一棵树,这棵树就是最终的MST树。
Kruskal 算法的正确性源自所谓的分割性质
分割性质 :设边集 X 是 $G = (V, E)$ 的某个生成树的一部分,选定任一节点集合 $S \subset V$,使得 X 中没有跨越 S 和 $V - S$ 的边。若 e 是跨越 S 和 $V - S$ 的权重最轻的边,则 $X \cup {e}$ 也是某个 MST 的一部分。
有:对任意的分割,在 X 不含跨越分割的边(该边的一个端点属于 S,另一个端点属于 $V - S$ )这一前提下,增加跨越该分割的权重最轻的边 e 总是安全的。
假设 X 是某个 MST T 的一部分,① e 恰好也在 T 中,无需证明;② e 不属于 T,通过改变 T 中的一条边可以构造一个与之不同的 MST T’,使得 T’ 包含 $X \cup {e}$;由于 T 是连通的,在 T 中必然存在一条路径连接 e 的两个端点,故增加 e 将形成一个环,这个环包含另外某条跨越分割 ${S, V - S}$ 的边 e’,将其移除,得到 $T’ = T \cup {e} - {e’}$;③ 性质① 可证 T’ 是连通的;另,T’ 和 T 的边数相同,性质② 和 性质③ 可知,T’ 也是树。
树T’ 代价:$ weight(T’) = weight(T) + w(e) - w(e’)$,e 是跨越 S 和 $V - S$ 的权重最轻的边 ,有 $w(e) \leq w(e’)$,从而 $weight(T) \leq weight(T’)$,由 T 是 MST,可知 $weight(T) = weight(T’)$,T’ 也是 MST。
Kruskal 最小生成树算法实现细节
起始于一个空的图。
通过逐条增加边来构造最小生成树:假如在构建最小生成树的过程中,我们已经选择了某些边并在向着正确的方向前进,下一步选择那条边呢?
不断重复地选择未被选中的边中权重最轻的且不会形成环的一条。
为保证连接等价类边的权值最短,算法首先对图中所有边按照权值进行排序。按权值由小到大依次选择边
不会形成环:每次选择一条边加入到现有的部分解中 ===> 需要检验每一条侯选边(u->v) 的端点是否属于不同的连通分量,一旦选定了某条边,则将这条边添加到 MST 并将两个相关的连通分量将被合并。
Kruskal 最小生成树算法关键数据结构:并查集/分离集 (union-find/disjoint sets)
Kruskal 算法开始有 n 个分别包含一个节点的集合(即 n 个分离集);随着算法的进展,分离集的个数逐渐减少,直到算法的最后一步,分离集的个数变为 1,此时产生最小生成树。
并查集:并查集处理的是集合之间的关系,即 union,find。在这种数据类型中,N个不同元素被分成若干个组,每组是一个集合,这种集合叫做分离集合。并查集支持查找一个元素所属的集合和两个元素分别所属的集合的合并。注意:并查集只能进行合并操作,不能进行分割操作。
并查集支持以下操作:
makeset(x):创建一个仅包含 x 的独立集合(分离集);最初每个节点单独构成了一个分离集 ==> 一组分离集find(x):不断重复地检验节点对,判断其是否属于同一个集合?union(x, y):每当增加了一条边,将与之相关的两个集合合并。
并查集的实现原理
并查集是使用树结构实现的
初始化:准备 N 个节点来表示 N 个元素,最开始没有边。
为避免树的退化,对于每棵树,记录其高度 rank。
查询:查询两个节点是否在同一个集合,只需要查询他们是否具有相同的根。
合并:从一个分离集的根向另一个分离集的根连边,这样两棵树就变为了一棵树,也就把两个集合合并为一个了;除非将要合并的树等高,否则将不会出现合并后总高度增加的情形;如果合并时两棵树高度不同,那么从 rank 小的向 rank 大的连边。
路径压缩:每次 find 操作中,当循着一系列的父指针最终找到树的根后,改变所有这些父指针的目标,使其直接指向树根。
通过路径压缩,所有节点的等级都不会发生改变;节点的 rank 不再能解释为其下方子树的高度
union 操作只关注树的顶层,路径压缩不会对 union 操作产生影响,它将保持树的顶层不变
find 操作(不论是否采用路径压缩)仅仅触及树的内部
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <iostream> #include <assert.h> /* assert */ using namespace std ; #define MAX_VERTEX_NUM 26 class UnionFindSets {private : int PI[MAX_VERTEX_NUM]; int rank[MAX_VERTEX_NUM]; int size; public : UnionFindSets(int size) { this ->size = size; for (int vertexIdx=0 ; vertexIdx<size; vertexIdx++) { PI[vertexIdx] = -1 ; rank[vertexIdx] = -1 ; } } void makeset (int x) assert(x >= 0 && x < size); PI[x] = x; rank[x] = 0 ; } int find (int x) assert(x >= 0 && x < size); if (x != PI[x]) { PI[x] = find(PI[x]); } return PI[x]; } void unite (int x, int y) assert(x >= 0 && x < size); assert(y >= 0 && y < size); int rx = find(x); int ry = find(y); assert(rx >= 0 && rx < size); assert(ry >= 0 && ry < size); if (rx == ry) { return ; } if (rank[rx] > rank[ry]) { PI[ry] = rx; } else { PI[rx] = ry; if (rank[rx] == rank[ry]) { rank[ry] += 1 ; } } } void printset () cout << "<Union&Find set>: " << endl ; for (int i=0 ; i<size; i++) { cout << "\tPI[" << i << "]: " << PI[i] << " " << "rank[" << i << "]: " << rank[i] << endl ; } } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 #include <iostream> #include <stdio.h> /* stdin */ #include <limits.h> /* INT_MAX */ #include <assert.h> /* assert */ #include <queue> /* priority_queue */ using namespace std ; #define MAX_VERTEX_NUM 26 class UnionFindSets {private : int PI[MAX_VERTEX_NUM]; int rank[MAX_VERTEX_NUM]; int size; public : UnionFindSets(int size) { this ->size = size; for (int vertexIdx=0 ; vertexIdx<size; vertexIdx++) { PI[vertexIdx] = -1 ; rank[vertexIdx] = -1 ; } } void makeset (int x) assert(x >= 0 && x < size); PI[x] = x; rank[x] = 0 ; } int find (int x) assert(x >= 0 && x < size); if (x != PI[x]) { PI[x] = find(PI[x]); } return PI[x]; } void unite (int x, int y) assert(x >= 0 && x < size); assert(y >= 0 && y < size); int rx = find(x); int ry = find(y); assert(rx >= 0 && rx < size); assert(ry >= 0 && ry < size); if (rx == ry) { return ; } if (rank[rx] > rank[ry]) { PI[ry] = rx; } else { PI[rx] = ry; if (rank[rx] == rank[ry]) { rank[ry] += 1 ; } } } void printset () cout << "<Union&Find set>: " << endl ; for (int i=0 ; i<size; i++) { cout << "\tPI[" << i << "]: " << PI[i] << " " << "rank[" << i << "]: " << rank[i] << endl ; } } }; struct adjVertexNode { int adjVertexIdx; int weight; adjVertexNode* next; }; struct VertexNode { char data; int vertexIdx; adjVertexNode* list ; int cost; VertexNode* prev; }; struct Edge { int fromIdx, toIdx; int weight; bool operator < (const Edge& right) const { return weight > right.weight; }; }; struct Graph { VertexNode VertexNodes[MAX_VERTEX_NUM]; int vertexNum; int edgeNum; }; void CreateGraph (Graph& g) int i, j, edgeStart, edgeEnd, weight; adjVertexNode* adjNode; cin >> g.vertexNum >> g.edgeNum; for (i=0 ; i<g.vertexNum; i++) { cin >> g.VertexNodes[i].data; g.VertexNodes[i].vertexIdx = i; g.VertexNodes[i].list = NULL ; g.VertexNodes[i].prev = NULL ; } for (j=0 ; j<g.edgeNum; j++) { cin >> edgeStart >> edgeEnd >> weight; adjNode = new adjVertexNode; adjNode->adjVertexIdx = edgeEnd; adjNode->weight = weight; adjNode->next = g.VertexNodes[edgeStart].list ; g.VertexNodes[edgeStart].list = adjNode; } } void PrintAdjList (const Graph& g) cout << "The adjacent list for graph is:" << endl ; for (int i=0 ; i < g.vertexNum; i++) { cout << " " << g.VertexNodes[i].data << "->" ; adjVertexNode* head = g.VertexNodes[i].list ; if (head == NULL ) cout << "NULL" ; while (head != NULL ) { cout << g.VertexNodes[head->adjVertexIdx].data << "(" << head->weight << ") " ; head = head->next; } cout << endl ; } } void DeleteGraph (Graph& g) for (int i=0 ; i<g.vertexNum; i++) { adjVertexNode* tmp = NULL ; while (g.VertexNodes[i].list != NULL ) { tmp = g.VertexNodes[i].list ; g.VertexNodes[i].list = g.VertexNodes[i].list ->next; delete tmp; tmp = NULL ; } } } void Kruskal (Graph& g) UnionFindSets sets (g.vertexNum) ; priority_queue<Edge> EdgeQueue; for (int i=0 ; i<g.vertexNum; i++) { sets.makeset(g.VertexNodes[i].vertexIdx); adjVertexNode* head = g.VertexNodes[i].list ; while (head != NULL ) { Edge e; e.fromIdx = g.VertexNodes[i].vertexIdx; e.toIdx = head->adjVertexIdx; e.weight = head->weight; EdgeQueue.push(e); head = head->next; } } cout << "\nMST constructing: " << endl ; while (!EdgeQueue.empty()) { Edge e = EdgeQueue.top(); EdgeQueue.pop(); if (sets.find(e.fromIdx) != sets.find(e.toIdx)) { if (g.VertexNodes[e.toIdx].prev != NULL ) { continue ; } g.VertexNodes[e.toIdx].prev = &g.VertexNodes[e.fromIdx]; g.VertexNodes[e.toIdx].cost = e.weight; cout << "\t+ " << g.VertexNodes[e.fromIdx].data << "-->" << g.VertexNodes[e.toIdx].data << "(" << e.weight << ")" << endl ; sets.unite(e.fromIdx, e.toIdx); } } } void PrintMST (Graph& g) int cost = 0 ; for (int i=g.vertexNum-1 ; i>=0 ; i--) { if (g.VertexNodes[i].prev != NULL ) { cout << "\t+ " << g.VertexNodes[i].data << "<--" << g.VertexNodes[i].prev->data << "(" << g.VertexNodes[i].cost << ")" << endl ; cost += g.VertexNodes[i].cost; } } cout << " cost: " << cost << endl ; } int main (int argc, const char ** argv) freopen("Prim.txt" , "r" , stdin ); Graph g; CreateGraph(g); PrintAdjList(g); Kruskal(g); cout << endl ; cout << "Minimum Spanning Tree: " << endl ; PrintMST(g); DeleteGraph(g); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ g++ Kruskal.cpp -o Kruskal $ ./Kruskal The adjacent list for graph is: 0->7(8) 1(4) 1->2(8) 0(4) 2->8(2) 5(4) 3(7) 1(8) 3->5(14) 4(9) 2(7) 4->5(10) 3(9) 5->6(2) 4(10) 3(14) 2(4) 6->8(6) 7(1) 5(2) 7->8(7) 6(1) 0(8) 8->7(7) 6(6) 2(2) MST constructing: + 6-->7(1) + 5-->6(2) + 8-->2(2) + 2-->5(4) + 1-->0(4) + 2-->3(7) + 2-->1(8) + 3-->4(9) Minimum Spanning Tree: + 7<--6(1) + 6<--5(2) + 5<--2(4) + 4<--3(9) + 3<--2(7) + 2<--8(2) + 1<--2(8) + 0<--1(4) cost: 37
整棵最小生成树的构建过程如下: